October 30, 2025
Update: On October 31, arXiv tightened moderation in its computer science category. Review/survey articles and position papers will now be posted only with proof of prior peer-reviewed acceptance at a journal or conference; submissions without documentation will likely be rejected.
On a Friday afternoon at Cornell University, I knocked on Paul Ginsparg’s office to talk about arXiv, a public open-access research repository of preprints (papers shared before peer review) he built in 1991, and why he now sees Large Language Models ( LLMs) as “an existential threat to the entire enterprise.” The conversation was a part of my ongoing ethnographic research on how AI and everyday practices of science mutually shape each other; specifically, I am interested in how AI is changing laboratory life — how scientists reason, what they trust, and what now counts as a good argument as AI becomes part of their daily work. Paul told me his worries began with a graph he’d been analyzing that showed a spike in arXiv rejections since 2023, the year LLMs like ChatGPT became widely used. But the real alarm sounded on a hiking trail in the Adirondacks, when he was discussing the situation with his son, who asked him a simple question: How do people who aren’t in the research community even know about arXiv?
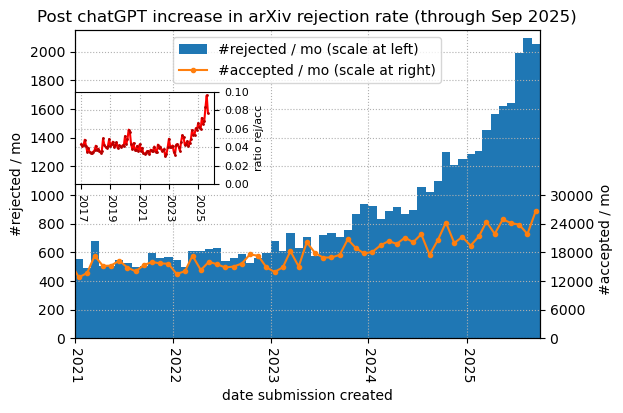
Figure 1: Post ChatGPT increase in arXiv rejection rate through September 2025 (shared with the author by Paul Ginsparg)
His son turned to his phone. With just a few quick prompts to a LLM — “How do I publicize my new theory of the universe?” — they watched as an entire strategy unfurled. The model offered a journal-style abstract, then generated a complete LaTeX paper (with figures and references), and finally provided step-by-step instructions for submitting to arXiv. When his son asked if it would be a problem to submit a paper without research or expertise in the field, the model advised registering with an institutional email, since arXiv treats affiliation as a credibility marker. In under five minutes, without any technical content, the system had assembled a professional-looking paper and pointed directly to arXiv as the obvious next step.
“Hook, line, and sinker,” Paul described it to me later: ChatGPT and other LLMs now manufacture a form of scholarship, funnel the user to a well-known venue, and explain how to bypass the usual social checks. It’s not that novel ideas can’t come from outside academia; of course they can. The issue is that the polish in their presentation no longer indicates the amount of effort put into a paper or the merit of its arguments.
Unpacking “career review”
ArXiv has never been about peer review; its mission has always been rapid, open dissemination of research and scholarship with only light-touch moderation. As Paul put it, arXiv’s filter is less “peer review” and more “career review.” In tight-knit research communities, a seasoned moderator could often apply what he calls “the one look approximation to peer review” — a quick scan to see if a paper signaled a lack of engagement with a research community’s literature and methods (for example, “Einstein is wrong”). Such papers aren’t rejected because novel ideas are unwelcome, but because they do not demonstrate an understanding of why their claims are so improbable or acknowledge the work that has already addressed them. Most submissions that clear this basic socialization check move forward. But that “one look” depends on social context: knowing the authors, the community, the subfield, the kinds of ongoing arguments that recur within the discipline. For decades, that context made the system both agile and resilient.
And that’s precisely what breaks in the LLM era. “The abstract could look reasonable… even isolated paragraphs,” Paul explained, but “you couldn’t see that something was very wrong until you actually tried to follow the logic.” Grand claims are made in the abstract and introduction, but such papers often “never even get back to them in the conclusion,” leaving “gigantic missing… steps and arguments.” Moderators who once skimmed ten to fifteen abstracts per day are now confronted with prose that is fluent but hollow. Papers that are grammatically polished, citation-laden and yet completely meaningless can, in Paul’s words, “frequently be impossible to spot, unless you do more careful reading.” The signal (good writing) no longer tracks the thing it signaled (good work). “Subliminally, we imagine that quality of prose is a signal used by reviewers. And with LLMs, that signal could be inverted,” he said. Instead of revealing substance, fluency can now mask its absence.
Paul’s data supports the gut check. In September 2025 alone, arXiv received a record 26,000 submissions. Rejection rates — historically low and stable — have climbed sharply since 2023. The surge isn’t from long-time contributors “going to the dark side,” he told me; it’s primarily from new submitters who learned, in minutes, how to produce the trappings of a research paper. Some of it happens in good faith after sustained over-encouragement from LLMs: as an example, Paul pointed to a news story about a man who spent three weeks this year certain he’d discovered a new branch of math. Some is overt CV padding (content-free “surveys,” mutual-citation loops that inflate metrics). Either way, volume rises; in response, moderators’ scrutiny must shift from surface fluency to argumentative substance. This shift is healthy; reviews should prioritize argument over gloss. But arXiv is not the venue for such reviews. It’s a place where papers are shared before they are reviewed. Without better ways of identifying AI slop, this shift only adds more work for moderators — slowing the process and stretching their capacity to manage submissions effectively.
Adding to these challenges is the continued reliance on institutional emails as a stand-in for credentials. Once a pragmatic gate that helped established communities grow, institutional domains were never meant to confer authority. Alumni accounts, hospital affiliations, and departmental listservs make them leaky signals at best, and now LLMs actively teach newcomers to exploit the shortcut. The result isn’t just more submissions; it’s a new layer of false authority. When a chatbot says, “use an institutional email” it turns an informal heuristic into an instruction manual.
Sustaining arXiv’s credibility — and what it needs from us
ArXiv works because communities use it, challenge each other, and crucially, debunk findings that don’t stand up to deeper scrutiny. Its strength lies in the habits of its users, and how they use it to drive research conversations. But the lesson of the LLM moment is this: presentation is now cheap. And when fluency is automated, the burden of scrutiny shifts.
To sustain arXiv as a credible source for scientific papers, Paul has been prototyping detectors that move past surface polish: analyzing text density, stop-word patterns, the telltale bullet-point slide structures common to LLM outputs, and subtle traces of machine translation that can expose paragraph-level paste-ups. This isn’t about building a blunt “AI detector.” Many uses are benign; for example, non-native speakers cleaning up prose. But for triage, these filters can help surface submissions that deserve a closer human look.
There also needs to be a deeper discussion on routing all first-time submissions through genuine human endorsements — co-authors or colleagues who can vouch for the reasoning and argumentation of the paper — rather than treating institutional email as automatic validation. Additional levers that can be appropriated across communities include adding friction in especially high-volume categories, and improving moderator tooling so anomalies are visible earlier and effort is targeted where it matters. None of this is a major departure from the tradition of “career review;” they’re principles for evolving guardrails in a changed information environment.
With a need for social and epistemic work to move closer to where papers first appear, everyone has a role to play. To begin with, researchers submitting papers to arXiv can adopt two practical norms:
- Don’t outsource your argument. Using a model to clean up prose is one thing. Asking it to invent steps you can’t defend is another. If your abstract promises a testable hypothesis, show your work.
- Don’t take openness for granted. ArXiv’s speed exists because the community is trusted to act in good faith. Misuse of openness invites added friction for everyone.
It’s not only researchers who bear responsibility. LLMs largely mirror the policies and public guidance they’re trained on. As arXiv clarifies and surfaces its guardrails against AI slop, model answers will likely shift accordingly — away from nudging first-time, unaffiliated users toward arXiv and toward venues that provide more structured feedback.
The world still needs what arXiv uniquely offers: speed, openness, and a durable public record of an ongoing scientific conversation. Speed without quality controls is spam; openness without responsibility is an invitation to slop. Writing scientific papers with LLMs requires owning up to the difference between good writing and good reasoning, and rebuilding the light-touch filters that let the former get out of the way of the latter.
